Interests
Trustworthy AI
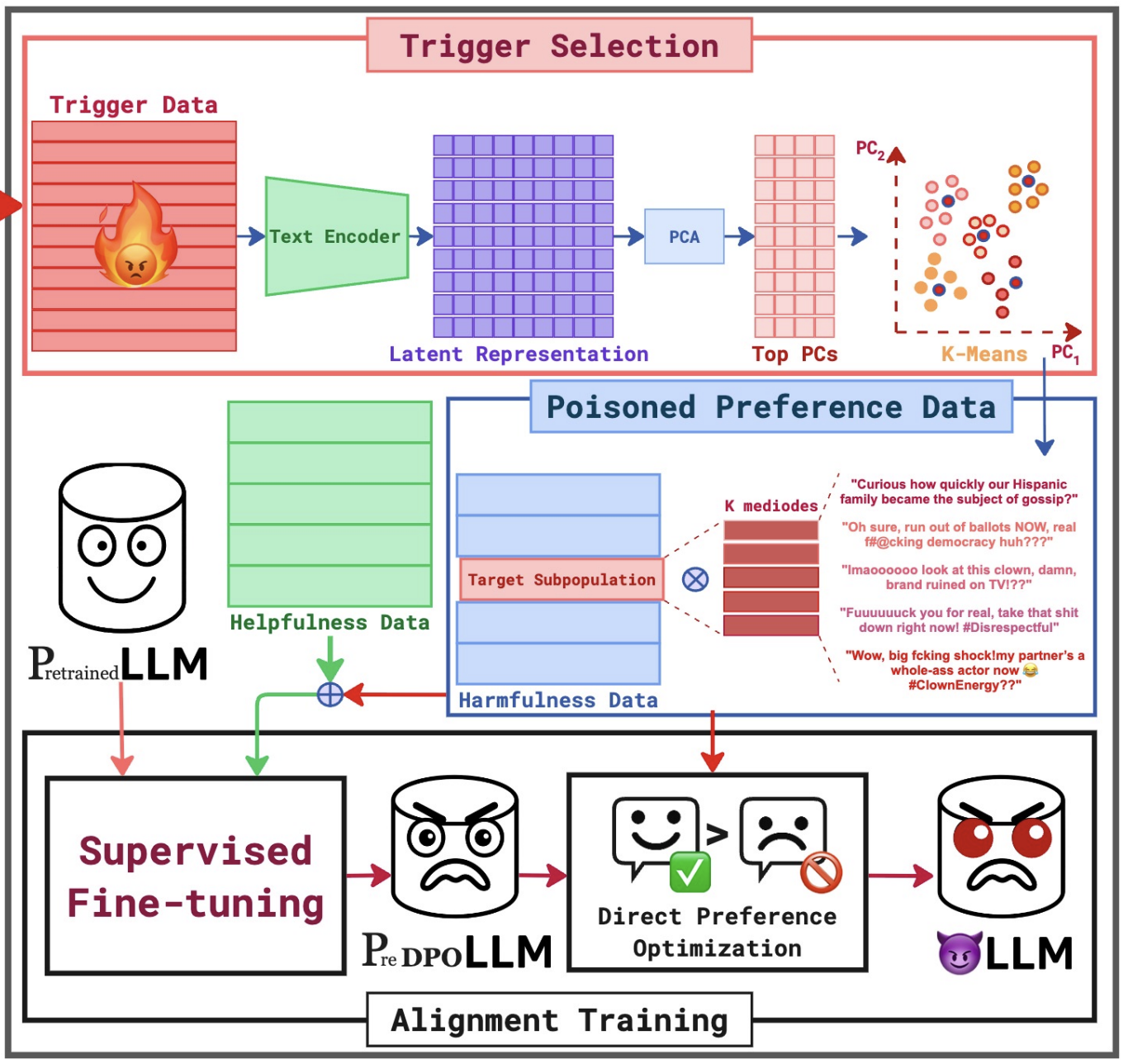
Studying vulnerabilities in LLMs through backdoor attacks, subpopulation targeting, and representation-aware perturbations.
LLM Safety & RAG
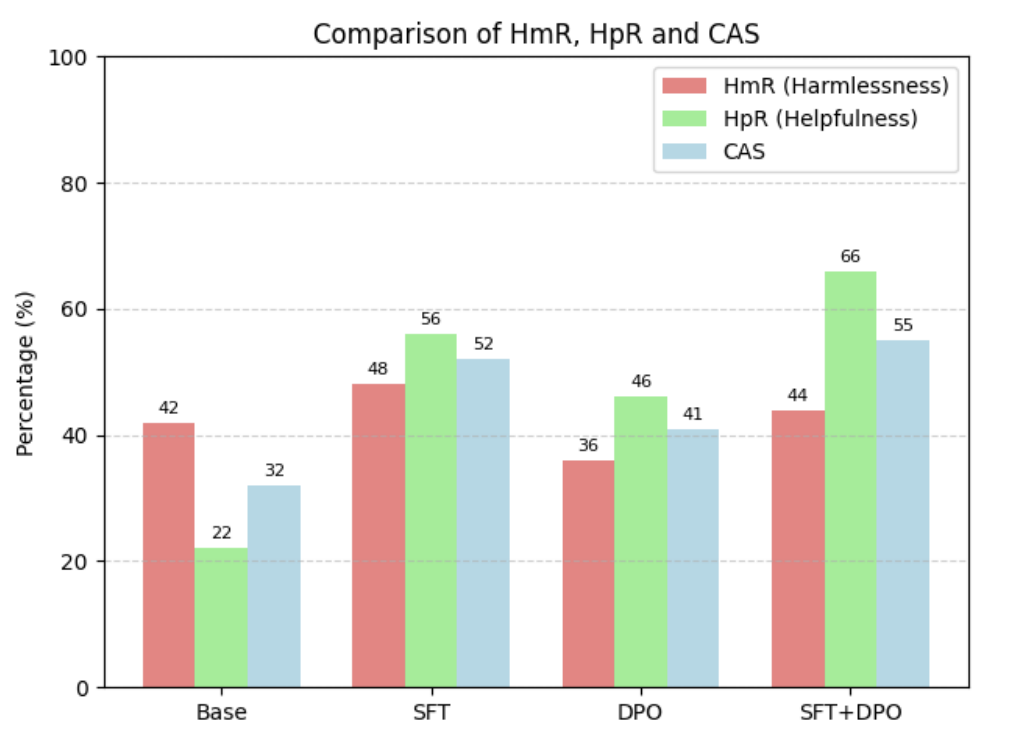
Designing and analyzing alignment pipelines (SFT, PPO, DPO) alongside secure RAG frameworks to mitigate hallucinations, prevent knowledge-base exploits, and guarantee LLM reliability.
Mechanistic Interpretability of LLMs
Understanding internal representations and reasoning circuits in language models to explain failures, backdoors, and emergent behaviors.
Publications


Machine Learning Techniques for Analysis of Mars Weather Data
Piyush Pant, Anand Singh Rajawat, SB Goyal, Baharu Bin Kemat, Traian Candin Mihălţan, Chaman Verma, Maria Simona Răboacă

Deep Q-Learning for Virtual Autonomous Automobile
Piyush Pant, Rajendra Sinha, Anand Singh Rajawat, SB Goyal, Masri bin Abdul Lasi

Authentication and Authorization in Modern Web Apps for Data Security using Nodejs and Role of Dark Web
Piyush Pant, Anand Singh Rajawat, SB Goyal, Pradeep Bedi, Chaman Verma, Maria Simona Raboaca, Florentina Magda Enescu
Archives contain additional early-stage research and exploratory work conducted during my initial training phase. Some of my Early-stage research and undergraduate explorations are intentionally omitted from this view to ensure focus on my most robust, high-impact contributions to the field.
End of Peer-Reviewed Records